
哈希表
组别:提高组
难度:6
散列表(Hashtable,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。这种方式不需要进行任何的比较,其查找的效率相较于前面所介绍的查找算法是更高的。
哈希技术的基本思想是通过由哈希函数决定的键值。(key)与哈希地址(H(x.key))之间的对应关系来实现存储组织和查找运算,哈希技术的核心是哈希函数。
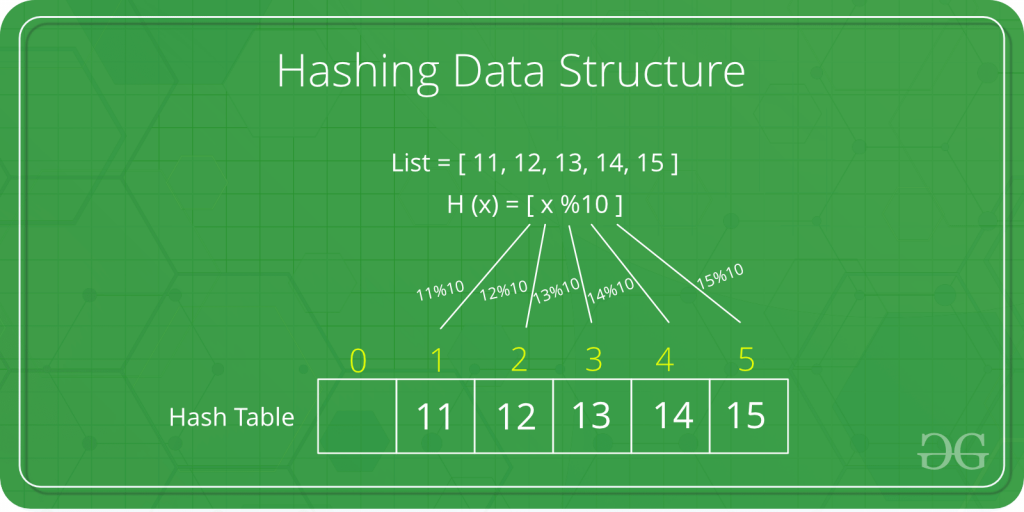
这里有一个电话簿(查找表),电话簿中有 5个人的联系方式:
张三 13911879643
李四 13309876542
王五 13498456821
赵六 13546738294
孙七 13648391025
假如想查找王四的电话号码,对于一般的查找方式最先想到的是从头遍历,一一比较。而如果将电话簿构建成一张哈希表,可以直接通过名字“李四”直接找到电话号码在表中的位置。哈希函数为:每个名字的姓的首字母的 ASCII 值即为对应的电话号码的存储位置。
哈希冲突
张三和赵六两个关键字的姓的首字母都是 Z ,最终求出的电话号码的存储位置相同,这种现象称为冲突。
即:不同关键字通过哈希函数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
哈希函数设计原则:
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。 所以哈希函数设计原则:
1、哈希函数的定义域必须包括需要存储的全部关键码
2、如果散列表允许有m个地址时,其值域必须在0到m-1之间
3、哈希函数计算出来的地址能均匀分布在整个空间中
4、哈希函数应该比较简单
哈希冲突的避免
通常用的处理冲突的方法有以下几种:
1、开放定址法
H(key)=(H(key)+ d)MOD m(其中 m 为哈希表的表长,d 为一个增量) 当得出的哈希地址产生冲突时,选取以下 3 种方法中的一种获取 d 的值,然后继续计算,直到计算出的哈希地址不在冲突为止,这 3 种方法为:
线性探测法:d=1,2,3,…,m-1
二次探测法:d=12,-12,22,-22,32,…
伪随机数探测法:d=伪随机数
2、再哈希法
当通过哈希函数求得的哈希地址同其他关键字产生冲突时,使用另一个哈希函数计算,直到冲突不再发生。
3、链地址法
将所有产生冲突的关键字所对应的数据全部存储在同一个线性链表中。
数值哈希函数构造方法
1、直接定制法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)=a*Key +b 优点:简单、均匀 缺点:需要事先知道关键字的分布情况 使用场景:适合查找比较小且连续的情况 面试题:字符串中第一个只出现一次字符。
2、除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:
Hash(key) = key% p(p<=m),将关键码转换成哈希地址 。
3、平方取中法–(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址; 再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址 平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况。
4、折叠法–(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况。
5、随机数法–(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。通常应用于关键字长度不等时采用此法。
6、数学分析法–(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况
哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
字符串哈希函数构造方法
构造字符串哈希函数通常是为了快速比较字符串的相等性或者用于字符串的查重等场景。常见的字符串哈希函数使用的是 Rolling Hash 技术,基于多项式哈希的思想。下面是一个基本的字符串哈希函数的实现思路和示例代码。
哈希函数的构造步骤
- 选择基数和模数:
- 基数
base:一般选择一个大于字符串字符集大小的质数,比如26、31、或其他合适的质数。 - 模数
mod:选择一个大的质数,避免哈希冲突,一般选取如10^9 + 7或2^61-1。
- 基数
- 计算哈希值:
- 对于给定的字符串
s,其哈希值可以表示为: hash(s)=(s0×basen−1+s1×basen−2+⋯+sn−1×base0)mod mod - 其中,
s_i是字符串的第i个字符的 ASCII 码值,n是字符串的长度。
- 对于给定的字符串
- 滚动更新(用于子串的哈希比较):
- 对于长度为
n的子串s[i:j],如果已经计算了s[i:j-1]的哈希值,则s[i+1:j]的哈希值可以通过在O(1)时间内从s[i:j]的哈希值推导出来。
- 对于长度为
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | /**************************************************************** * Description: 字符串哈希函数 * Author: Alex Li * Date: 2024-08-13 14:47:13 * LastEditTime: 2024-08-13 14:48:34 ****************************************************************/ #include <iostream> #include <vector> #include <string> using namespace std; // 哈希函数配置 const int base = 31; const int mod = 1e9 + 7; /*compute_hash 函数: 计算字符串 s 的前缀哈希值并存储在 hash_values 数组中。 使用了 base 和 mod 来计算哈希值,避免溢出并减少哈希冲突。 */ vector<long long> compute_hash(const string &s) { int n = s.size(); vector<long long> hash_values(n + 1, 0); // 哈希值数组 long long hash = 0; long long power = 1; for (int i = 0; i < n; i++) { hash = (hash + (s[i] - 'a' + 1) * power) % mod; hash_values[i + 1] = hash; power = (power * base) % mod; } return hash_values; } //get_substring_hash 函数:用于计算子串的哈希值,这里利用前缀哈希值的性质,在常数时间内计算子串的哈希。 long long get_substring_hash(int l, int r, const vector<long long> &hash_values, const vector<long long> &powers) { long long hash_r = hash_values[r]; long long hash_l = hash_values[l - 1]; return (hash_r - hash_l + mod) % mod; } int main() { string s = "hello"; vector<long long> hash_values = compute_hash(s); // 输出整个字符串的哈希值 cout << "Hash of the string: " << hash_values[s.size()] << endl; return 0; } |